2 years ago
Over the last year we could witness an unprecedented surge in the research and deployment of new leading-edge machine learning models. Although these have already proven themselves to offer useful applications, the gains usually come at the cost of increasing data demands. This naturally results in challenges related to the high cost of data processing, but even more importantly, raises justified concerns about data privacy and protection.
In the light of already well-established policies, such as the GDPR and recent policies introduced by the EU AI Act, we want to point out some techniques that allow companies to comply with the new regulations. In this blog mini-series, we will focus on the concept of Federated Learning (FL), a decentralized machine learning paradigm that aims to preserve information privacy by enabling data scientists to train models without needing to move the relevant data from place to place.
In this blog article, we will introduce the theory behind the FL approach, along with examples of existing applications. In future articles, we will discuss the main risks and challenges in FL, as well as software frameworks that support FL implementation.
Why Federated Learning?
In a classic machine learning context, raw data is often collected from distributed sources, such as private databases or edge devices, and then moved to a centralized storage space. From there, it usually goes through a number of pre-processing steps, and is then used to train a model. However, transferring data exposes it to the risk of interception and often conflicts with the data owner’s obligations to ensure privacy. This is particularly concerning when we collaborate with sectors where confidentiality has the utmost priority, as in the case of healthcare or financial institutions. In those cases, it may sometimes be impossible to share any private information that concerns patients or customers.
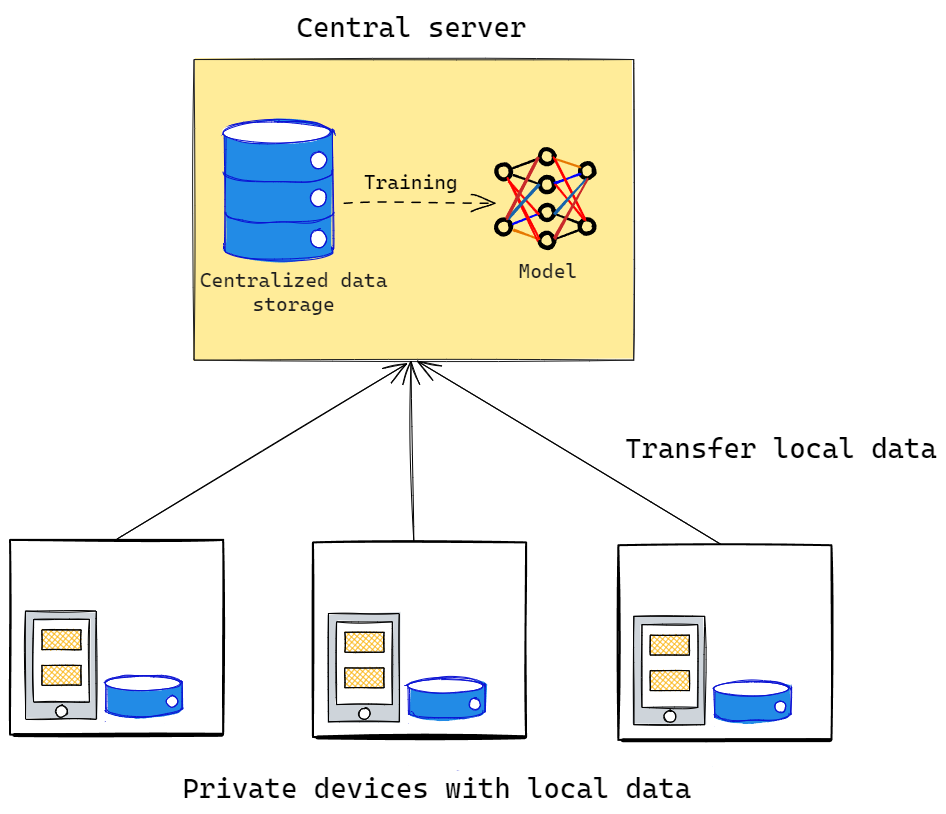
Fig. 1 Classical machine learning workflow
Instead, FL proposes a distributed training scheme, where each private machine trains a model on its local chunk of data, and then sends information about the model’s parameter updates to a global model that resides on the central server. In that way, local data never leaves its owner, which significantly reduces the risk of privacy breaches.
Let’s take a closer look at the steps in a basic FL workflow.
Federated Learning Workflow
- Before training starts, the global model is initialized on the central server, and each FL participant (we will refer to them as ‘client nodes’ or simply ‘clients’) downloads a copy of the model.
- Each client starts training its local model on the private data. Although the model’s architecture is shared across clients, the training hyperparameters or even optimizers can differ between the individual nodes. These can be adjusted, depending on the characteristics of the local dataset. Local training usually doesn’t run for longer than one epoch.
- After the training step, clients transfer their local model updates to the central server, where the changes are combined together in order to update the global model weights. This is referred to as the ‘aggregation’ step, and its specific implementation depends heavily on the model architecture used and the task that is being addressed. One of the most common examples of the aggregation mechanism is ‘Federated Averaging’ (FedAvg), in which weights of the global model are updated with the average of all the local models’ weights. In practice, a weighted averaging scheme is often applied, where the influence of each local model is scaled according to the local dataset size or other quality markers.
- Finally, the local models stored in the client nodes are updated with the new global model. There are also varying ways of executing this update, and replacing the old model version completely with the new one is not the only option. For instance, in some cases, both models can be combined together, which results in more customized performance on each node.
Steps 2-4 above are repeated until the global model reaches convergence.
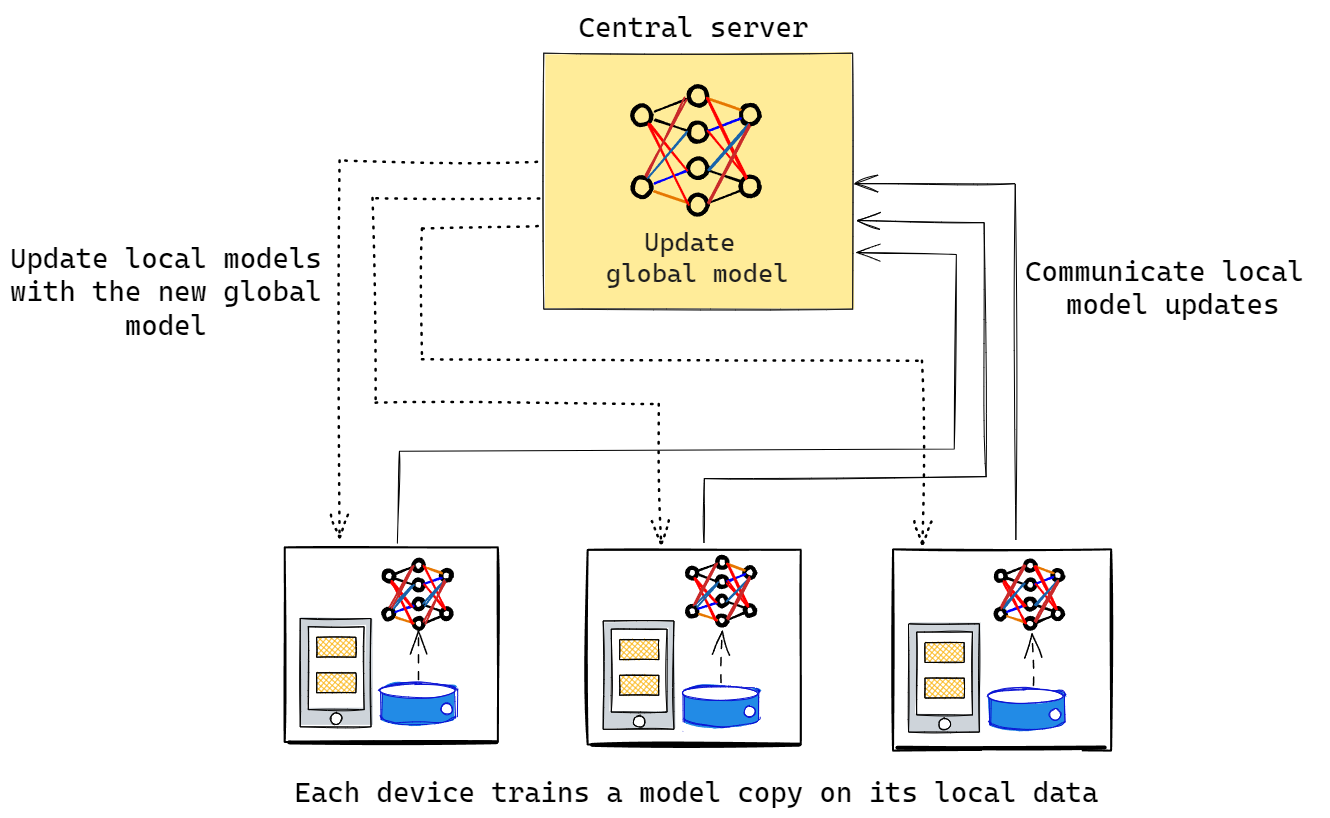
Fig. 2 Basic FL workflow
At this point, it’s important to mention that the workflow described above is the simplest one, but it is not the only approach to creating federated models. The workflow is often modified in order to meet the specific applications or different privacy constraints, and this may involve additional steps. Discussion of all the possible workflows is out of the scope of this post, but we can recommend the following articles to those with a deeper interest in the topic [1, 2]. Instead, we would like to briefly introduce the different FL categories that you are likely to encounter in real-world scenarios.
Federated Learning Categories
The literature distinguishes three main types of FL that are related to the properties of the decentralized datasets:
- Horizontal Federated Learning (HFL): in this case, the overlap of data features between client datasets is greater than the overlap of data instances. In other words, each client stores different samples, but the samples are described by a set of highly similar features. For example, multiple hospitals may keep standardised medical records of patients, but each hospital has data from different individuals.
- Vertical Federated Learning (VFL): this is opposite to HFL, where there is a large sample overlap, but each client owns a different set of features. You can imagine a scenario where one financial institution has access to a customer’s transaction history, but another party holds information about the individual’s demographics, and they would like to jointly train a fraud detection model by leveraging both sets of features.
- Federated Transfer Learning (FTL): in this case, datasets owned by each client are assumed to differ greatly in both sample space and feature space. This scenario often applies to related, but technically different, businesses (for example, a bank and an e-commerce company), that are also located in different geographical regions (hence the small samples intersection). Using the Transfer Learning [3] techniques combined with the training scheme laid down by the FL, it is possible to leverage the existing similarities and obtain a model that performs well in either feature space.
Each of the above categories may require a different training scheme or computing architecture. In general, we distinguish two main types of FL architectures as follows:
- Centralized Federated Learning (CFL): this is like the basic workflow described above, with a single central server acting as an orchestrator that first coordinates training executed by clients and then aggregates the updates.
- Decentralized Federated Learning (DFL): an alternative approach, where each node transmits its local updates to all the participating nodes, and aggregates the incoming updates into its local model. This approach eliminates the dependence on any central orchestrator.
Federated Learning Applications Examples
Since its first introduction by Google researchers in 2016 [4], FL has been successfully adopted to problems in various industries. Here, we can give some more specific examples:
- Smartphones: Google’s Keyboard (Gboard) is a classic example in that area, and one of the first global-scale FL implementations. This approach was used to improve Gboard’s query suggestions with next-word prediction language models. [5, 6] All of that was achieved with on-device learning and without exporting user data to external servers.
- Healthcare: FL was used in the task of predicting the future oxygen requirements of patients with Covid-19, where researchers employed data from 20 institutes across the globe to collaboratively train a chest X-ray model [7]. In another case, an FL-based convolutional network model was developed to assist in the diagnosis of cancer patients [8].
- Finance: [9] describes an example of FL application for credit risk scoring models, where the application is particularly beneficial for smaller financial institutions without access to large datasets. In [10], the authors introduce an FL framework for collaborative training of models for detecting fraudulent transactions, where this approach also aligns with the Explainable AI principles.
Besides that, FL finds its application in fields like: smart cities [11], smart transportation [12], or intrusion detection [13].
Summary
As you could see, FL is an extremely broad topic with far-reaching implications for sectors prioritizing data privacy and collaborative model development. Hopefully, our brief overview shed some light on the most important concepts, and sparked your interest in the areas of potential applications. In the next article of this series, we will delve into the unique risks and challenges that need to be addressed when working within the FL framework.
References
[1] Beltrán, Enrique Tomás Martínez, et al. "Decentralized federated learning: Fundamentals, state of the art, frameworks, trends, and challenges." IEEE Communications Surveys & Tutorials (2023).
[2] Liu, Ji, et al. "From distributed machine learning to federated learning: A survey." Knowledge and Information Systems 64.4 (2022): 885-917.
[3] Torrey, Lisa, and Jude Shavlik. "Transfer learning." Handbook of research on machine learning applications and trends: algorithms, methods, and techniques. IGI global, 2010. 242-264.
[4] McMahan, Brendan, et al. "Communication-efficient learning of deep networks from decentralized data." Artificial intelligence and statistics. PMLR, 2017.
[5] Hard, Andrew, et al. "Federated learning for mobile keyboard prediction." arXiv preprint arXiv:1811.03604 (2018).
[6] Yang, Timothy, et al. "Applied federated learning: Improving google keyboard query suggestions." arXiv preprint arXiv:1812.02903 (2018).
[7] Dayan, Ittai, et al. "Federated learning for predicting clinical outcomes in patients with COVID-19." Nature medicine 27.10 (2021): 1735-1743.
[8] Ma, Zezhong, et al. "An assisted diagnosis model for cancer patients based on federated learning." Frontiers in Oncology 12 (2022): 860532.
[9] Lee, Chul Min, et al. "Federated Learning for Credit Risk Assessment." HICSS. 2023.
[10] Awosika, Tomisin, Raj Mani Shukla, and Bernardi Pranggono. "Transparency and privacy: the role of explainable ai and federated learning in financial fraud detection." IEEE Access (2024).
[11] Putra, Karisma Trinanda, et al. "Federated compressed learning edge computing framework with ensuring data privacy for PM2. 5 prediction in smart city sensing applications." Sensors 21.13 (2021): 4586.
[12] Elbir, Ahmet M., et al. "Federated learning in vehicular networks." 2022 IEEE International Mediterranean Conference on Communications and Networking (MeditCom). IEEE, 2022.
[13] Tang, Zhongyun, Haiyang Hu, and Chonghuan Xu. "A federated learning method for network intrusion detection." Concurrency and Computation: Practice and Experience 34.10 (2022): e6812.