1 year ago
Ever since the development of the first computer chess engines in the 1950s, their performance has consistently improved. As newer, more powerful machines became available, even just running the same algorithms on these upgraded systems resulted in increasingly accurate move predictions and stronger play. Over the years, these engines gradually closed the gap to human players, eventually defeating the world chess champion in 1997. However, their dominance didn’t end there. As the engines grew even stronger, they no longer faced challenges from human players, and the only competition left was other increasingly powerful engines.
Then in 2017, AlphaZero emerged. AlphaZero was a revolutionary AI-based approach that completely surpassed the top engines of the time, marking the beginning of a new era in the evolution of chess engine design. This shift - similar to what is currently being seen in a wide range of more practical applications across industries - compelled other engines to either innovate or fall behind, leading to intriguing solutions and potentially offering insights into how to navigate the AI revolution.
To grasp the full nature of the innovation introduced by AlphaZero, it is first essential to understand the algorithms that powered the leading chess engines of that era.
At its core, these engines relied on a concept known as the game tree, which can be visualised by starting from a single chess position and branching out to represent all possible legal moves that a player could make. This process is repeated for every subsequent position, ultimately constructing a tree that encapsulates every potential sequence of moves from that starting point to the end of the game.
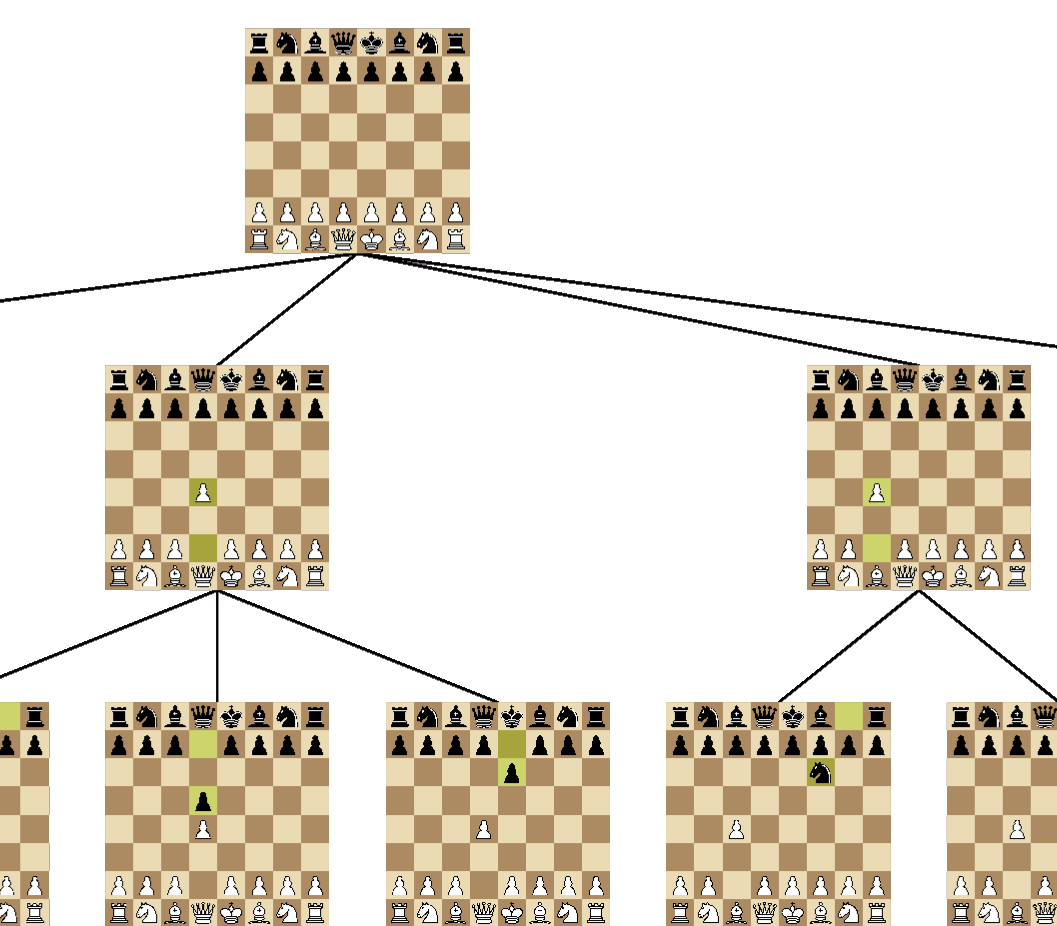
Partial game tree visualisation - generated with COTM
Once the game tree is constructed, the min-max algorithm is applied to evaluate the outcomes. The final positions at the leaves of the tree are assigned values as follows: +1 for a win, 0 for a draw, and -1 for a loss, according to the rules of the game. The algorithm then works backwards through the tree, assigning values to parent nodes based on either the minimum or the maximum value of all the child nodes depending on whose move it is. This alternation ensures that each node reflects the best strategy for both sides. By recursively applying this evaluation process across the entire tree, the algorithm effectively labels every position with its optimal value. With the tree completed, the engine can then determine the best course of action by simply selecting a move leading to the position with the highest/lowest score.
However, there is a significant limitation to this method: the immense size of the game tree makes a complete brute-force computation unachievable for any computer. Estimates suggest that the size of this tree is approximately 10^44 positions1, which is a number comparable to the total number of water molecules on Earth. Such an astronomical figure makes it impossible to calculate the entire tree.
To address this, chess engines rely on heuristic algorithms, which allow them to approximate optimal solutions by focusing on a more manageable subset of the game tree. These algorithms limit the depth and breadth of their game tree analysis while still producing strong results. The foundation of this approach lies in evaluating positions directly. Instead of waiting for a game to reach a terminal state where it can be definitively scored as +1, 0, or -1, the engine assigns a numerical value to intermediate positions, reflecting the relative advantage of one player over the other.
A straightforward method for such evaluation involves assigning point values to chess pieces and calculating the difference in their totals for each player. For instance, a queen might be worth nine points, a rook five points, and so on. This basic evaluation mirrors how many human players assess positions during a game. However, both humans and engines can refine this further by incorporating more sophisticated factors. For example, they might assign higher values to centralised pieces, which typically exert greater influence on the board, or might factor in metrics like king safety, which reflects how vulnerable a player’s king is to attack.
Armed with this heuristic evaluation method, we can revisit the min-max algorithm, limiting the recursion depth to a manageable level. With additional resources such as extended time or increased computational power, the search depth can be incrementally extended, yielding progressively more precise assessments of potential moves and positions. To optimise performance, engines can also discard less promising branches of the game tree, focusing computational efforts on more promising lines. However, this selective exploration must be approached carefully. Prematurely dismissing certain moves risks missing strategic opportunities, such as those involving temporary sacrifices that could lead to a substantial advantage later in the game.
AlphaZero took an entirely different path, discarding the conventional methods in favour of reinforcement learning. Through this approach, it trained a deep neural network capable of selecting the optimal move directly. Of course, if provided with additional time, this method could still be used to analyse future positions in the game tree, gradually refining its assessments.
This groundbreaking strategy proved to be overwhelmingly effective. AlphaZero dominated its competition, outperforming traditional engines even when playing at 1/10 time odds. Its success showcased the power of AI-based techniques and highlighted a new era in chess engine development.
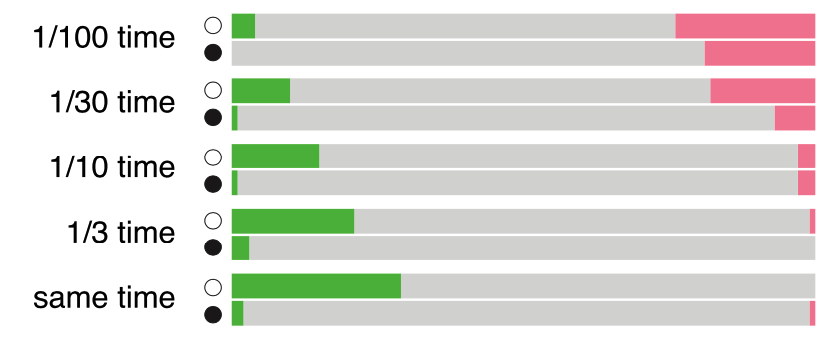
AlphaZero's results (wins in green, losses in red) vs Stockfish 8 in time odds matches
source: https://www.chess.com/news/view/updated-alphazero-crushes-stockfish-in-new-1-000-game-match
Rather than employing a large, deep network to determine precise moves, it integrates a smaller, faster model designed to enhance heuristic evaluations. This compact network replaces the traditional evaluation function at the leaf nodes of the search tree, enabling it to analyse the entire board and identify patterns that would have been overlooked by conventional methods. By doing so, it effectively extends its vision beyond just the calculated depth.
The heart of this system is NNUE (efficiently updatable neural network). It optimises performance by leveraging the fact that, when it evaluates many similar positions, some intermediate outputs of this network can be reused, eliminating the need to recompute them repeatedly. This not only accelerates processing, but also mitigates one of the primary weaknesses of the deep learning models which, ironically, is its relatively low depth (in terms of the length of the considered lines).
By blending this efficient neural network design with its powerful traditional algorithms, Stockfish managed to retain its speed while significantly enhancing its positional understanding, with later iterations gradually solidifying its dominance in the chess world.
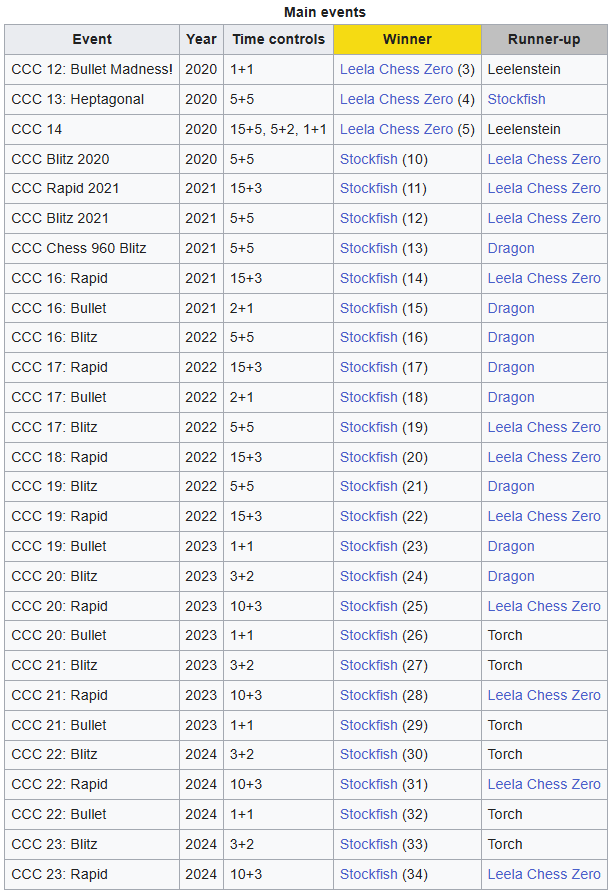
Chess.com Computer Chess Championship results since 2020
To illustrate the contrast between these two approaches, we can examine a key position from the first game of the 2024 World Chess Championship. In this instance, Ding made the move Nb2, which, although not immediately intuitive from a human perspective, proved to be pivotal in securing his ultimate victory.
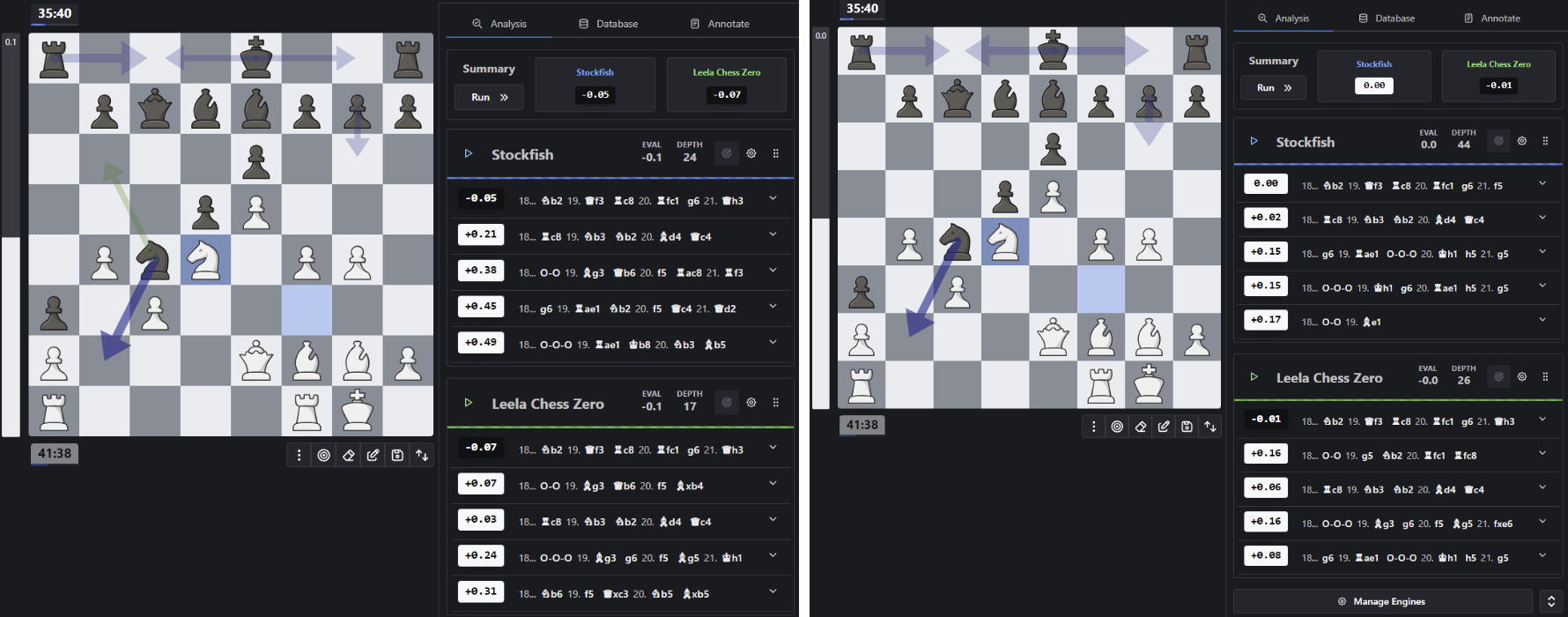
Position analysis (using the en-croissant chess toolkit) at move 18 from Game 1 in the 2024 World Chess Championship
When analysing this move with both engines, they both identified Nb2 as the strongest option within approximately 10 seconds of calculation and selected an identical set of top five moves after about 10 minutes of processing. However, the distinction between the two becomes apparent when comparing the depths of their calculations - Stockfish reached a depth of 44, whereas Leela analysed to a depth of 26. This discrepancy highlights the differing methodologies of the engines, even when their final evaluations tend to align.
Finding a position that effectively demonstrates these differences is a challenge. However, it is reasonable to expect that Stockfish might excel at identifying a line leading to a tangible advantage, such as winning material after 40 moves (within its calculated depth). On the other hand, Leela could position its pieces with greater strategic harmony, achieving an advantage that evades Stockfish’s simpler evaluation function, with its full strength becoming evident only beyond Stockfish’s 44-move horizon.
I believe that, while the practical applications might initially seem distant (though perhaps less so now, given the current AI boom), there is much to learn from this rivalry between the chess engines. This is true not only from a technical standpoint, where these solutions can be adapted to address a variety of other challenges, but also on a broader conceptual level. In this instance, it became clear that even when a powerful and innovative approach emerges, it does not necessarily mean that all prior work must be set aside. On the contrary, such moments present an opportunity to draw from, and integrate, the strengths of established ideas, leading to the creation of a solution that, as demonstrated in this case, has the potential to be even more effective than either approach on its own.
1 https://github.com/tromp/ChessPositionRanking