3 years ago
We all have that one uncle in the family who knows the answer to every question. Even if that answer is often wrong. Let’s call him Uncle Bob. From politics to science, he confidently shares his opinion on every possible topic. Did you know that we only use 10% of our brain? Or that chimpanzees use sign language to communicate? Talking to Uncle Bob often turns into a game of “fact or fiction” – trying to guess whether he is actually right or just making stuff up. I don’t know about you, but for me assuming the latter usually feels like the safest bet.
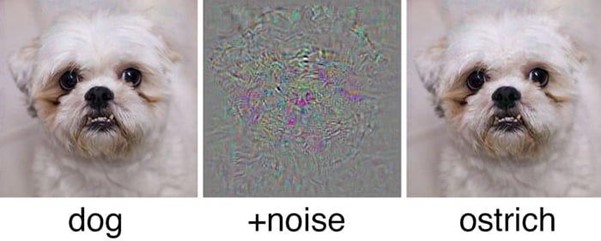
And what if I told you that neural networks are very much like Uncle Bob? They are famously overconfidently wrong. Just like our favourite uncle, they don't shy away from making bold assertions with unwavering conviction, even when they are clearly out of their depth. For example, let's consider a simple convolutional network trained to distinguish cats from dogs. It does so with very high precision and accuracy. But what happens if we ask the network what is in the following pictures?

The last one is a dog? Well, it certainly does not look like one. But hey, this network has never seen a bird before so it's no wonder that it does not understand what a bird is. It’s an out of distribution sample. And yet the model lacks the experience to recognize it as something new. We have seen similar things happening when taking objects out of their natural context or using (even tiny) adversarial patches to fool a neural network.
In the AI research community, there is a rather famous story about a neural network trained to distinguish between huskies and wolves (Ribeiro, 2016). Initially, the model seemed to tell them apart quite successfully, but it soon became apparent that something was off – seemingly clear examples were getting misclassified. It turned out that, instead of identifying the animals based on their physical characteristics, the neural network learnt to classify them based on the presence of snow in the picture (see the images below). In this case, the images with snow were classified as wolves, whilst the images without snow were classified as huskies. And while this can be ascribed to the (intentional!) choice of the training data (the data was clearly biased), it highlights, once again, how confidently wrong a neural net can be.

In other words, neural networks do not necessarily know when (and what) they don’t know. They're like a toddler, making inferences about the world based on their limited knowledge and not seeing that their knowledge is indeed limited. And while this gross overconfidence may be funny when it comes to distinguishing cats, dogs and wolves, in other, more serious scenarios, it may prove catastrophic.
For example, a neural network controlling a self-driving car may learn to keep it in its lane by watching the bushes on the side of the road. But what if there are no bushes? Would the model admit to being confused and hand the control of the car back to the driver? No, it probably wouldn’t. And what about healthcare – a neural network trained on a specific set of diseases may misdiagnose and lead to mistreatment of a patient who suffers from a condition previously unseen by the model. That could have fatal consequences for the patient. In such real-life scenarios, it is extremely important that models do not behave overconfidently and when in doubt, inform the user that they do not know and defer decisions to a human expert. Ideally, what we would like is for our models to exhibit high levels of uncertainty when dealing with data that is dissimilar to the data they have seen before. That mechanism would allow us to trust their predictions a little bit more.
But why are the neural networks so overconfident in the first place?
Well, this is a complex question and it has more than one correct answer. For starters, it’s important to acknowledge that classification-based models are not really learning what it means to be a cat or a dog, but rather how to spot the differences between the set of provided cat images (on the one hand) and the set of provided dog images (on the other hand). As a result, if you give your standard classifier a picture of a bird, it will not be able to use the fact that birds have wings to tell us that we’re not looking at either a cat or a dog - neither of the latter have wings. The way we train neural networks is also incredibly important – given insufficient amount of training data or biased training data, a complex neural network can easily pay too much attention to idiosyncrasies that are specific to the training set (like snow). And this leads to overconfident predictions when faced with new data, which is called "overfitting".
On the more technical side, the softmax activation function, commonly used in the last layer of the neural networks, converts the output of the last hidden layer (logits) into probability values summing up to 1. Due to the exponential involved in calculating the softmax function, small differences in logits can be translated into huge differences in the assigned probability score, which can again lead to overconfidence. Recently it has also been shown that ReLU-based networks produce predictions with arbitrarily high confidences far away from the training data (Hein et al., 2019). And most of the commonly used neural networks are indeed ReLu-based.
So can we do nothing to fix this? Are neural networks never going to recognize their own limitations?
It's hard to say, but it seems that there may be some hope on the horizon. The topic of estimating the trustworthiness of neural networks is gaining more and more traction, and as a result, promising solutions are starting to emerge. Some of the most prominent ones include:
1. Bayesian neural networks
As the name suggests, Bayesian neural networks (BNNs) use a Bayesian interface to provide probabilistic predictions and uncertainty estimates. Put simply, as illustrated in the image below, whereas in traditional neural networks weights are treated as point estimate values, in BNNs weights are treated as probability distributions. These distributions can then be used to estimate prediction certainty (Jospin et al., 2022). Unfortunately, although BNNs are powerful, they also suffer from several drawbacks. Since they require sampling from a posterior distribution of the weights, they can be computationally expensive, often making the training and inference slower than with the non-Bayesian neural networks. They also require specification of the prior distribution of weights and hyperparameters which can be challenging without specific expert knowledge.
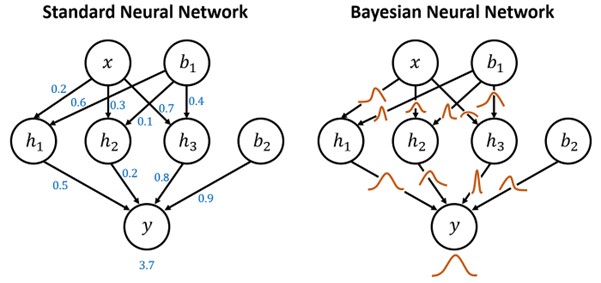
Image from: https://sanjaykthakur.com/2018/12/05/the-very-basics-of-bayesian-neural-networks/
2. Detecting out of distribution (OOD) samples
Instead of using Bayesian models, we could also try and detect when a sample shown to our neural network falls outside of the data distribution seen at training time. During inference time, for any given input, we would use a scoring function that quantifies the probability of that input being an OOD sample. This can be done by either using postprocessing techniques (DeVries & Taylor, 2018) or by integrating generative models, such as GANs, into the prediction pipeline (Lee et al., 2018). While post-hoc OOD detection does not interfere with our trained models, it is also not a perfect solution to the problem. As we have seen before, neural networks can produce overconfidently wrong predictions even for in-distribution images and with this approach, those cases would not be caught.
3. Quantifying model uncertainty
Ok, so what if instead of detecting OOD samples, we just focus on quantifying prediction certainty? For every input, we could generate a score that tells us how confident the model is. This way both the OOD samples and the difficult in-distribution samples should receive a low score. One of the techniques that could be used here is conformal prediction (Angelopoulos and Bates, 2022). With a given input, conformal prediction estimates a set of classes that are guaranteed to include a true label with a high probability value (where the value, for example 95%, is specified by the user), as in the image below. And unlike BNNs, this approach does not require us to change our model’s implementation or architecture. The estimated prediction set can include a single class, which indicates that our model is pretty sure of its output. It can also include each of the possible classes, which indicates that our model is not very certain. In an extreme scenario, the estimated set can even be empty, meaning that our model is genuinely unsure of what to do.
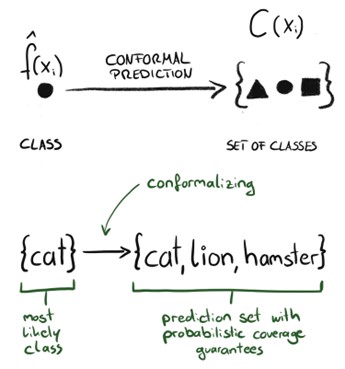
Image from: https://mindfulmodeler.substack.com
4. Learning to reject
Last, but not least, we could perhaps teach our neural network to simply say, “I don’t know”, and defer the task to a human expert (Hasan et al., 2023). The subfield in machine learning that deals with incorporating this capability is known as prediction with a reject option (or selective prediction). Here, before even learning the prediction function, we would pass each input through a rejection function that will tell us if it is even worth trying to make a prediction in this case. The use of the reject option ensures that the model refrains from making any decisions in cases of uncertainty and instead hands the task back to a human expert. It all sounds easy enough on paper, but designing an effective rejection function is a pretty challenging task.
In summary, hope is not lost – one day we may be able to tell just how trustworthy our neural nets are. But until then, we need to remember that just like Uncle Bob, neural networks are not omniscient and that, although they appear very confident, sometimes they simply do not know what they are talking about.