4 years ago
As humans, we have a visual system that allows us to see (extract and understand) shapes, colours and contours. So why do we see every image as a different image? How do we know, for example, that a box in an image is, in reality, a box? And how do we know what a plane is or what a bird is?
If you were to explain to someone how to spot a plane on an image, what would you say? That a plane is big? That it has a straight core section and two perpendicular plates in the middle of the core? That, more often than not, a plane is pictured on a blue background. But then how do we know that it's a plane and not a bird? This is what we will try to understand in this article.
And what is "context"? Context is any additional information that helps to establish relationships between the most relevant elements in a scene in order to enable a more coherent and meaningful interpretation. To investigate certain aspects related to context in an implicit manner, let's consider an example of carrying out inference on out-of-context images by using Faster R-CNN.

Which objects can you see in the image above, how would you interpret the objects and how would you interpret the relationships between those objects?
As a human, when looking at the image above, you probably see a person in a street, and that person is dragging a computer monitor along the street by pulling some kind of string or cable.
On the other hand, a trained FasterRCNN trained interprets the same image as follows:

In this case, the fact that the monitor is being dragged on the ground is not detected at all. This probably has to do with the fact that the model is:
- not used to detecting computer monitors that are in scenes which are outdoors (the probability of this happening is low); and
- (especially) not used to detecting computer monitors that are down by the feet of a person (such a relative position is unusual).
On the other hand, the model detects a "handbag". Although this is not correct, this does make some sense given that the item is near to the person's hand.
Any half-decent Data Scientist would say that the incorrect result is based on the fact that the training set didn't contain enough relevant data. However, have you ever seen a person dragging a monitor along on the leash? Probably not! On the other hand, as a human, you knew immediately that the object was not a handbag.
Let us consider some more examples.
We all know what a car is (and looks like). Equally, a neural network also knows what the car is, even in a weird context that was probably not there in the original dataset, as in the following examples:


Nevertheless, if we show to a neural network some cars which are upside-down and which are in a position above a person's head, these cars are either not detected at all or are detected as "planes".



So why does the neural network sometimes detect a given shape and structure as a car, and sometimes as a plane? What other factors can we check to find out what makes the difference?
We could argue that there are differences in the cars themselves which make it possible for the neural network to conclude that essentially the same objects are different types of objects. And that's true, but let's see what happens when we analyse the same objects in different contexts.
For example, in the picture below, I have added a plane above the bird:

We can see that the plane is correctly detected as a plane.
In the picture below, I have placed the plane in a position that is below the bird.

Aha! So, in this case, the plane is not detected at all if we place the plane below the bird.
In the next example, I have placed several copies of the plane all around the bird.

And now an object with the same features (a plane) is detected as a bird. Hmm, what has changed?
The context changed drastically from a plane being positioned below a bird to the same bird being surrounded by six objects. How often do we see planes very close to each other? And how often do we see birds close to each other either in small or large groups? What's more, how often do we see any birds flying above any planes?
It's starting to look as if the neural network is not only learning the individual features of an object, but is also learning features of the context of this particular object. In this way, the neural network is taking into account certain elements of the setting in the whole image.
In what other ways does the context change how a neural network detects objects?
Let's take a look at the image.
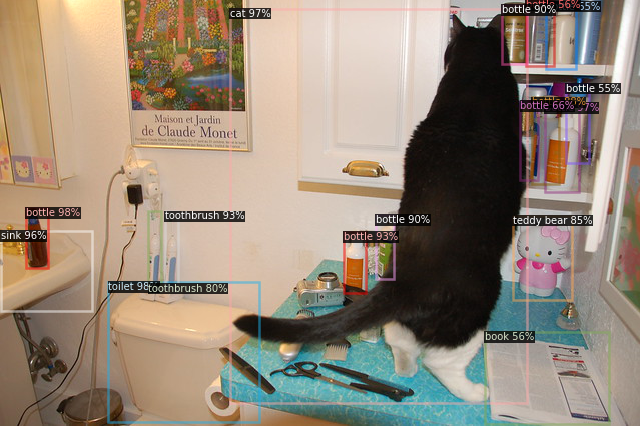
And now let's add a second cat:
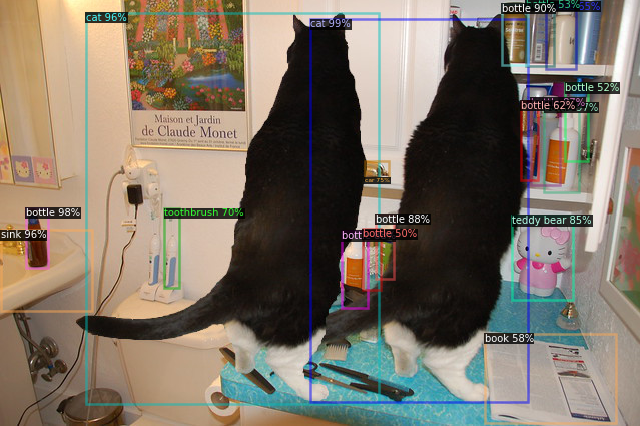
What differences can you see? On the face of it, everything seems to be fine. The second cat is correctly detected, but … what about detecting the two toothbrushes or the three bottles?
So adding a cat to the image has an effect on detecting a toothbrush! Isn't that weird?
Let's conclude with one final example. What if we take the background out completely, and then try to detect any remaining objects.

Hmm, a bear is detected as a "bird". I did not see that coming!
Let’s paste a small part of an image:

Oh dear! Our bear detector is really not doing a good job, is it? By adding a sheep to an image of a bear, the bear has become a sheep!
And what happens if we add noise to the background of the image:
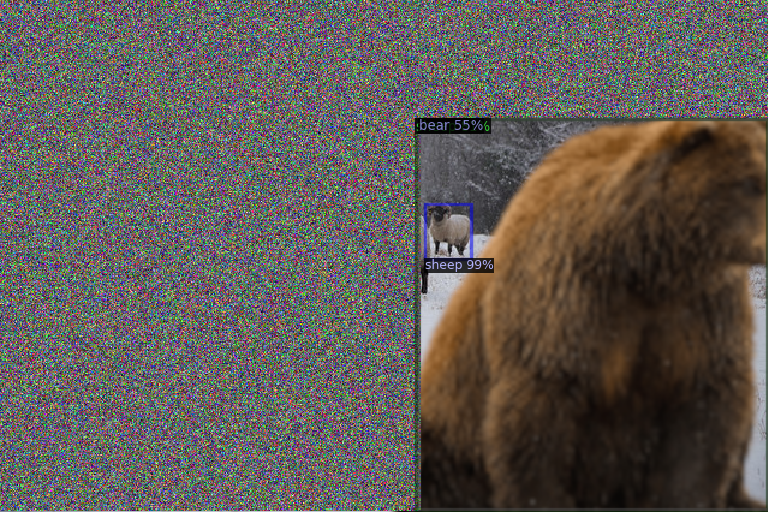
Ooh, that's an interesting result. Finally, we detected a bear!
So our results suggest that:
- A bear (on a black background) is a bird!
- A bear (on a black background with a sheep in the background) is a sheep!
- And, finally, a bear (with a sheep in the immediate background and then the bear/sheep image on a noisy back-background) is a bear!
I don't know about you, but I'm rather confused. What is a bear? What does a bear look like? How can we correctly detect a bear?
To summarise:
What we have seen is that different contextual clues can make a crucial difference to how well a neural network detects objects. And we see that, when designing our models and solutions, we must take into account clues such as:

As you can see, the object to be detected is not defined by the object itself. In addition to certain elements of the given object, neural networks also detect and try to process a lot of important, relevant contextual clues. As Data Scientists, we do not yet fully understand which factors directly influence the final quality of detections, but it is clear that we must always "bear" (pun intended) in mind that a single (seemingly irrelevant) change in one part of the image can have a dramatic effect on the final quality of the detection.
Resources:
https://arxiv.org/pdf/2101.06278v3.pdf
https://arxiv.org/pdf/2202.05930.pdf
https://github.com/shivangi-aneja/COSMOS