4 years ago
For some reason, it is quite natural for people to argue with each other all the time. Wives argue with husbands. Children argue with their parents. Facebook users argue with other Facebook users. United fans argue with City fans. And it goes without saying that … Data Scientists argue with other Data Scientists!

Whether the relationship is a professional one, or a personal one, it's inevitable that people will have different opinions. In fact, I would go so far as to say that arguing is a vital element in strengthening the bond between the people who are arguing, and that the process of arguing enables us to achieve more than if there were no "arguments". For example, a good marriage is not one that avoids arguments at all costs, but one in which the marriage partners know how to "argue" in a way which is constructive.
In the world of Data Science, you are faced with discussions and arguments all the time. Everyone has their own way of solving a given problem and, speaking for myself, this is something that I love about my job! But because we’re always dealing with uncertainties in the data, it is crucial to remember that:
No matter how certain you are that your statements are true, it is always possible that you can turn out to be wrong.
I am writing this article in the form of a confession. In this way, I hope that you learn from the mistakes that I have made as a Data Scientist.
Why it's always possible to be "wrong" in Data Science
In Software Engineering, most elements of the process have already been standardized, but it is more difficult to apply standardized concepts to Data Science. When developing a website, it is fairly easy to define the desired result, and therefore to estimate how long the development process will take. On the other hand, creating a model for Machine Learning includes many elements which are not standard, but require research and testing, and so creating a good, valid model might be a long and uncertain journey.
In Data Science, doing the required research work, or trying to come up with a custom solution, is a bit like being a child again. The process is similar to being given a set of lego blocks, and then having to figure out what the final building should look like. To do that, you swap different lego blocks around, arrange the blocks in different ways, and, over time, you get closer and closer to something that is similar to the building that you wanted to create in the first place.
In the field of Data Science, the “blocks” are:
- algorithms (as used for, amongst other tasks, classifying, clustering, and reducing dimensions, etc.)
- deep knowledge about the given field (for example, for a project on images, this includes knowledge about image properties, such as contrast, gradients, and blur, etc.)
- the knowledge that you gain from research papers, or other relevant sources of information.
Perhaps you're going to create a custom solution that no-one else has ever created with the above blocks. And you might start thinking that your new creation is going to be either a small breakthrough, or, even more exciting, a big breakthrough. In short, it's your creation, and you feel that it's your baby.

Just because you are right, does not mean that I am wrong
But is your "baby" really better than other people's "babies"?
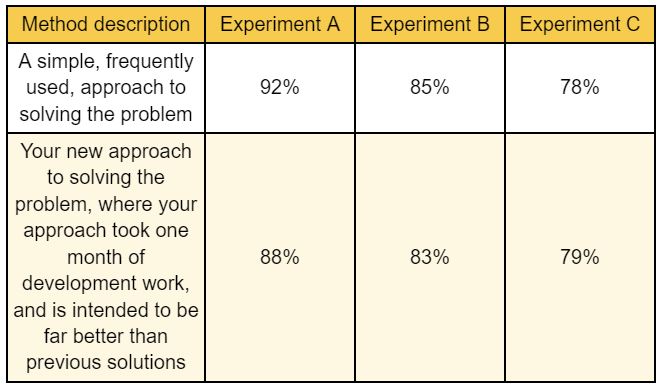
You know yourself: if you have created something, then you automatically assume that this something is better than all the other similar "somethings" that were created in the past. You find it very difficult to compare your creation with similar creations in a way which is objective, because you're convinced that your method outperforms the currently available methods. Let’s consider a concrete example by analyzing a table with the following results:
Case 1

After looking at the above results, you will probably come to conclusions which are something like this:
- The 1st method outperforms the 2nd method by 4% in experiment A, and by 2% in experiment B
- Also, the 2nd method is better than the 1st method in experiment C, by 1%
- Overall, it seems that the 1st method is slightly better than the 2nd method
Case 2
Now, let’s change the contents of the table a little bit:
Imagine that you review the above results. Here are just a few of the many possible conclusions that you could come to:
- “Hmm … something is not right …”
- “It really shouldn’t be like this …”
- “Maybe experiment A and experiment B are broken? I can't see much difference in them anyway ...”
- “The results are best in experiment C, so my method must be working …”
- “Or perhaps my method isn't working as it should? That would be too weird ...”
- “It's just not possible that the simple approach can be better than my approach, which was based on much more complicated thought-processes …”
Case 3
Now, let’s imagine that the results are reversed:

Yep, the conclusion is a no-brainer:
- “Well, obviously, my new method is better than the current, frequently used method.”
Taking the right approach to analysing test results
As you can see, my analysis above was not at all objective, but was rather biased (based on my expectations), because of my personal, emotional, connection to the thing that I had created. So, looking at the whole process, let’s summarize what was good, and what was not so good.
The good stuff:
- The fact that the test results were not what I was expecting forced me to start thinking about any external factors which could mean that the results of the test of my method seem to be worse than the true performance of my method. I was looking for someone, or something, to blame. But, next, because I was so determined to prove that my method was the best one, I then started to investigate the actual problem in a deep way
Eventually, I started asking myself questions about why my new method did not perform better than the previous one. This is important, because the key to really solving a problem lies in deep and thorough thought-processes. As Richard P. Feynman wrote: "The thing that doesn't fit is the thing that's the most interesting: the part that doesn't go according to what you expected."
The not so good stuff:
- I was reluctant to acknowledge that my method gave results that were either the same as, or actually worse than, the simple, frequently used method.
- If the test results had shown, on the face of it, that my method was better, I would not have questioned the results at all, but would have accepted the results at face value, and without the slightest hesitation. In fact, if someone else had questioned the test results, I would have defended my new method, rather than engaging in the process of testing my method in a meaningful way.
What are the takeaways from the above experience?
In conclusion, I would like to suggest that it's best if you always view your own creations in the following ways:
- Become very aware of your personal bias in favor of the things that you feel a close relationship to. Again, as Richard P. Feynman wrote: "The first principle is that you must not fool yourself, and you are the easiest person to fool".
- Take a genuine interest in everything, not only in the things which are directly relevant to what you're working on. Being curious, and trying to deeply understand the root of the problem, is an essential trait for any good Data Scientist.
- Always assume that what you think is "right" might in fact be "wrong". And search for the best evidence that you can find, in order to then make certain statements based on that evidence.
If you follow the above advice, not only will you become a better Data Scientist, but more importantly, a better person.